Изчисляване на коефициента на определяне в Microsoft Excel
Един от показателите, описващи качеството на конструирания модел в статистиката, е коефициентът на определяне (R ^ 2), който се нарича и стойността на надеждността на сближаването. С негова помощ можете да определите степента на точност на прогнозата. Нека да разберем как да изчисляваме този показател, използвайки различни инструменти на Excel.
съдържание
Изчисляване на коефициента за определяне
В зависимост от нивото на коефициента на определяне е общо да се разделят моделите на три групи:
- 0,8 - 1 - модел с добро качество;
- 0,5 - 0,8 - модел с приемливо качество;
- 0 - 0.5 - модел с лошо качество.
В последния случай качеството на модела показва, че не може да се използва за прогнозиране.
Изборът за изчисляване на зададената стойност в Excel зависи от това дали регресията е линейна или не. В първия случай можете да използвате функцията KVPIRSON , а във втория ще трябва да използвате специален инструмент от пакета за анализ.
Метод 1: изчисляване на коефициента на определяне за линейна функция
На първо място, нека да разберем как да намерим коефициента на определяне за линейна функция. В този случай този показател ще бъде равен на квадрата на корелационния коефициент. Ще го изчислим, като използваме вградената функция Excel, като използваме примера на конкретна таблица, която е показана по-долу.
- Изберете клетката, където коефициентът на определяне ще се изведе след изчислението й, и кликнете върху иконата "Вмъкване на функция" .
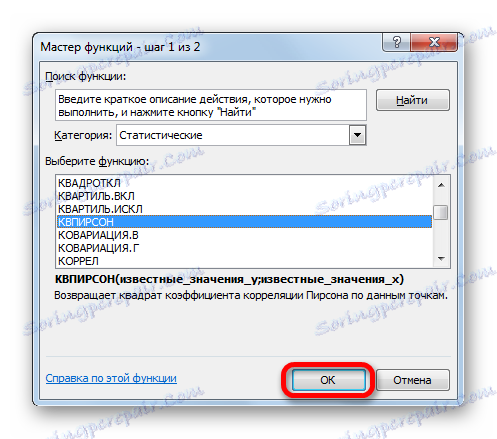
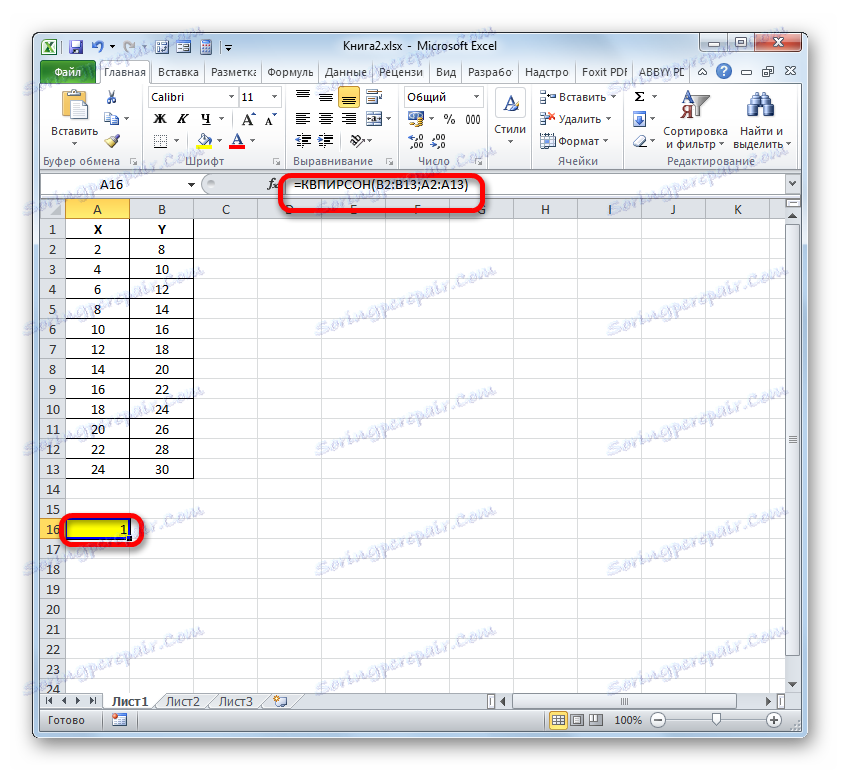
- Стартира съветникът за функции . Преминаваме в неговата категория "Статистика" и маркираме името "KVPIRSON" . След това кликнете върху бутона "OK" .
- Отваря се прозорецът с аргументи на функцията KVPIRSON . Този оператор от статистическата група се използва за изчисляване на квадрата на корелационния коефициент на функцията Pearson, т.е. линейната функция. И както си спомняме, с линейна функция коефициентът на определяне е точно равен на квадрата на корелационния коефициент.
Синтаксисът на това изречение е:
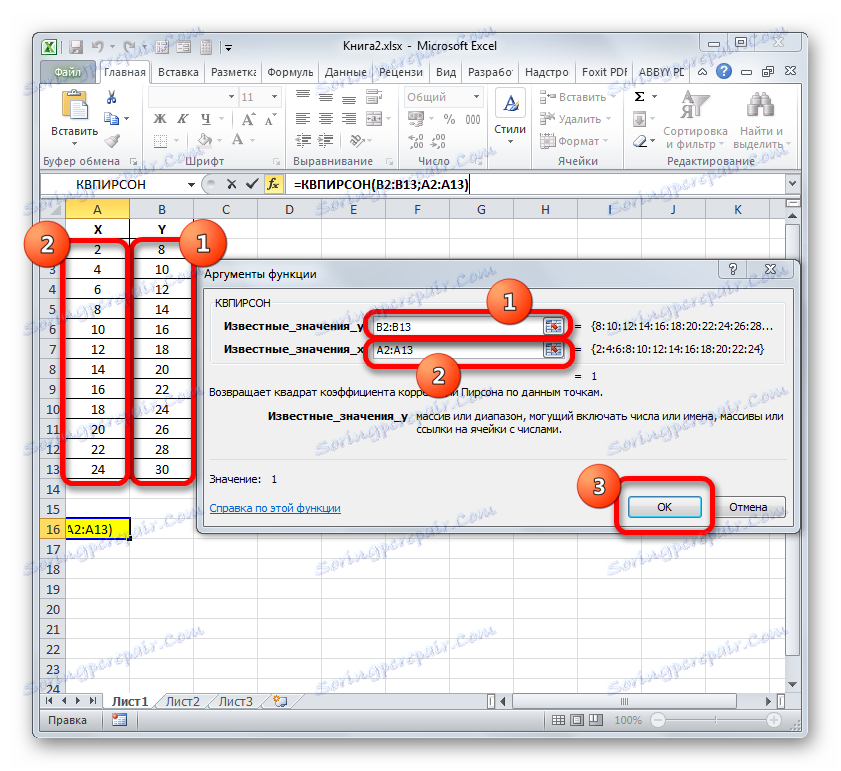
=КВПИРСОН(известные_значения_y;известные_значения_x)По този начин функцията има два оператора, единият от които е списък на стойностите на функцията и другият от аргументите. Операторите могат да бъдат представени като директно под формата на стойности, посочени чрез точка и запетая ( ; ), и като препратки към диапазоните, където се намират. Това е последният вариант, който ще използваме в този пример.
Задайте курсора в полето "Известно" . Захващаме левия бутон на мишката и избираме съдържанието на колоната "Y" на таблицата. Както можете да видите, адресът на посочения масив с данни се показва незабавно в прозореца.
По същия начин попълваме полето "Известни стойности на x" . Поставяме курсора в това поле, но този път избираме стойностите на колоната "X" .
След като всички данни бяха показани в прозореца на аргументите на KVPIRSON , кликнете върху бутона "OK", разположен най-долу в него.
- Както можете да видите, програмата след това изчислява коефициента на определяне и извежда резултата на клетката, която е била разпределена преди да се обади на помощника за функции . В нашия пример стойността на изчисления показател се оказва 1. Това означава, че представеният модел е абсолютно надежден, т.е. той елиминира грешката.
Урокът: Съветник за функции в Microsoft Excel
Метод 2: изчисляване на коефициента на определяне в нелинейни функции
Но горният вариант на изчисляване на желаната стойност може да се приложи само към линейни функции. Какво можем да направим, за да го изчислим в нелинейна функция? В Excel има и такава възможност. Това може да стане с помощта на инструмента "Regression" , който е неразделна част от пакета "Анализ на данните" .
- Но преди да използвате посочения инструмент, трябва да активирате самия "Анализен пакет" , който по подразбиране е деактивиран в Excel. Преминаваме към раздела "Файл" , след което отидете на "Опции" .
- В прозореца, който се отваря, отиваме в раздела "Добавки", като се придвижваме през лявото вертикално меню. Полето "Управление" се намира в долната част на дясната част на прозореца. От списъка с наличните подсекции изберете името "Добавки в Excel ..." и след това кликнете върху бутона "Отиди ..." вдясно от полето.
- Добавя се прозорец на добавката. В централната му част има списък с наличните добавки. Поставете отметка в квадратчето до елемента "Пакет за анализ" . След това кликнете върху бутона "OK" от дясната страна на интерфейса на прозореца.
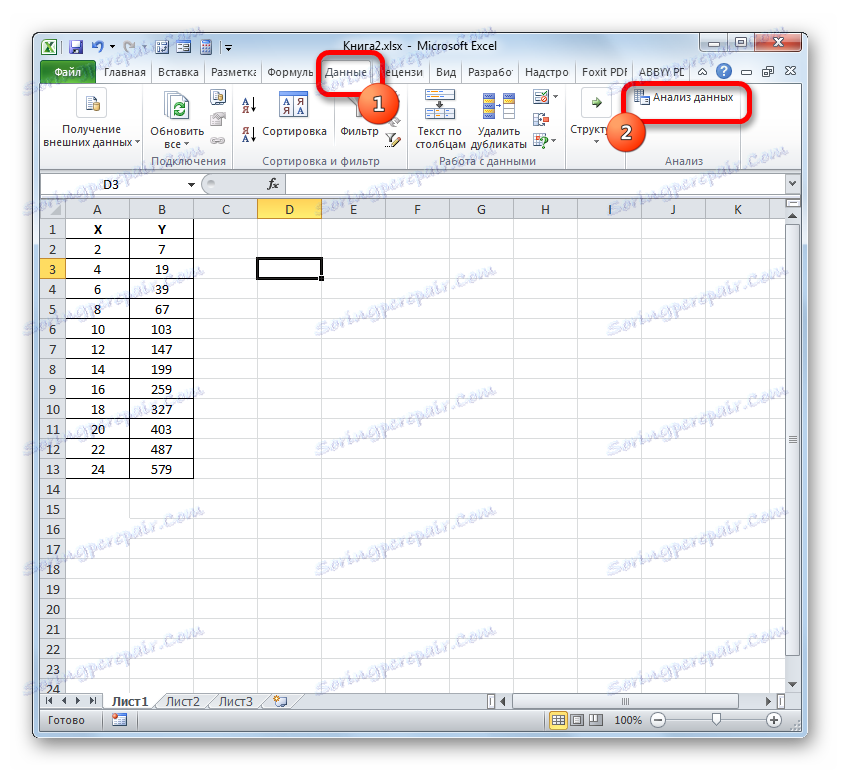
- Ще бъде активиран пакетът с инструменти "Анализ на данните" в текущото копие на Excel. Достъпът до него се намира на лентата в раздела "Данни" . Преместване до посочения раздел и кликване върху бутона "Анализ на данните" в групата с настройки "Анализ" .
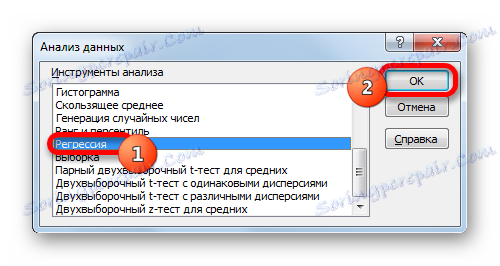
- Прозорецът "Анализ на данните" се активира със списък от инструменти за обработка на информация за профил. Избираме елемента "Регресия" от този списък и кликнете върху бутона "OK" .
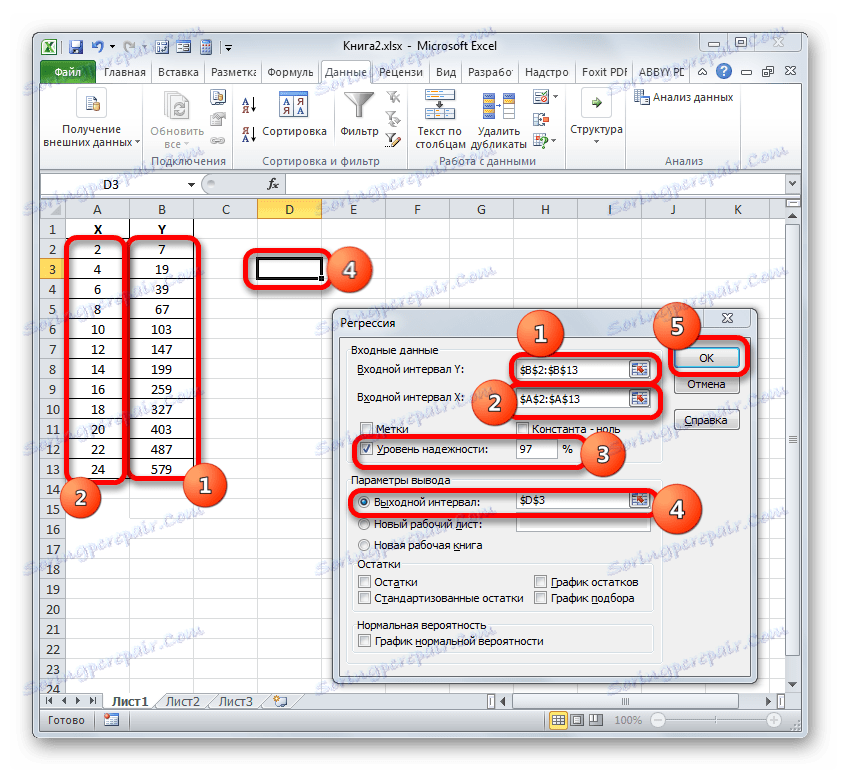
- След това се отваря прозорецът Regression tool. Първият блок от настройки е "Входни данни" . Тук, в две полета, трябва да посочите адресите на диапазоните, където се намират стойностите на аргумента и функцията. Поставяме курсора в полето "Интервал на въвеждане Y" и избираме съдържанието на колоната "Y" на листа. След като адреса на масива се покаже в прозореца "Регресия" , поставете курсора в полето "Интервал Y" и изберете клетките на колоната "X" по същия начин.
За параметрите "Label" и "Constant-zero" не поставяме квадратчетата за отметка. Полето за отметка може да бъде настроено в близост до параметъра "Ниво на надеждност" и в противоположното поле можете да зададете желаната стойност на съответния индикатор (95% по подразбиране).
В групата "Изходни параметри" трябва да посочите в коя област ще бъде показан резултатът от изчислението. Има три възможности:
- Площ на текущия лист;
- Друг лист;
- Друга книга (нов файл).
Ще спрем на първия вариант, така че оригиналните данни и резултатът да бъдат поставени на един работен лист. Поставете превключвателя около параметъра "Изходен интервал" . В полето, разположено срещу това поле, позиционираме курсора. Кликваме върху левия бутон на мишката върху празния елемент на листа, който е предназначен да стане горната горна клетка на изходната таблица на резултатите от изчисляването. Адресът на този елемент трябва да бъде откроен в полето "Регресия" .
Групите параметри "остава" и "нормална вероятност" се игнорират, тъй като те не са важни за решаването на задачата. След това кликнете върху бутона "OK" , който се намира в горния десен ъгъл на прозореца "Регресия" .
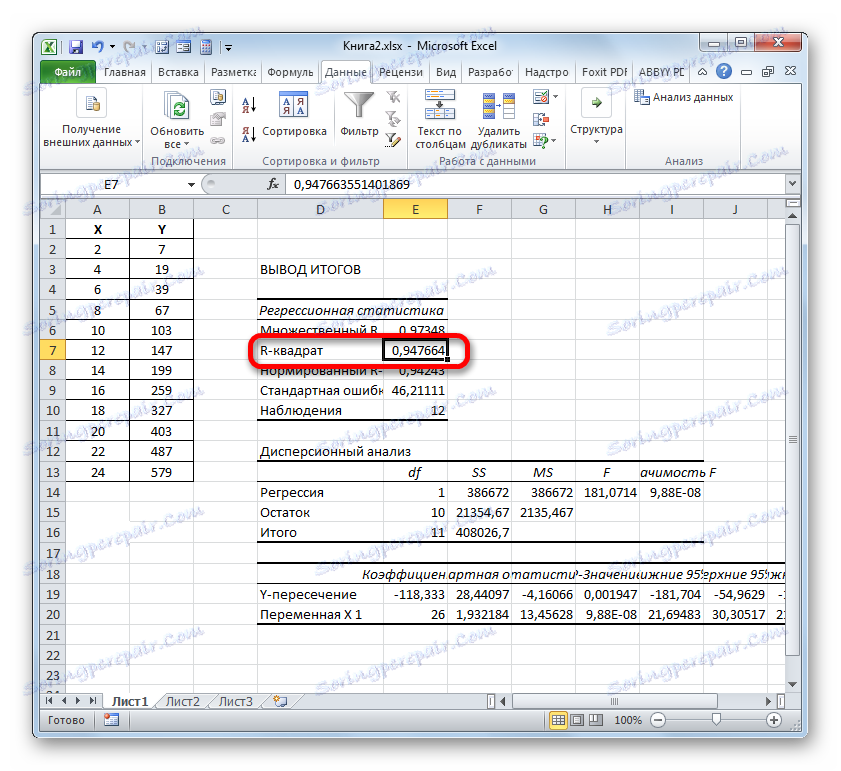
- Програмата се изчислява въз основа на въведените по-рано данни и извежда резултата до зададения диапазон. Както можете да видите, този инструмент показва голям брой резултати от различни параметри на листа. Но в контекста на настоящия урок се интересуваме от показателя "R-square" . В този случай тя е равна на 0.947664, което характеризира избрания модел като модел с добро качество.

Метод 3: Коефициент на определяне за линията на тенденцията
В допълнение към горните опции, коефициентът на определяне може да се покаже директно за тренд линията в графиката, изграден върху лист Excel. Нека да разберем как може да се направи това с конкретен пример.
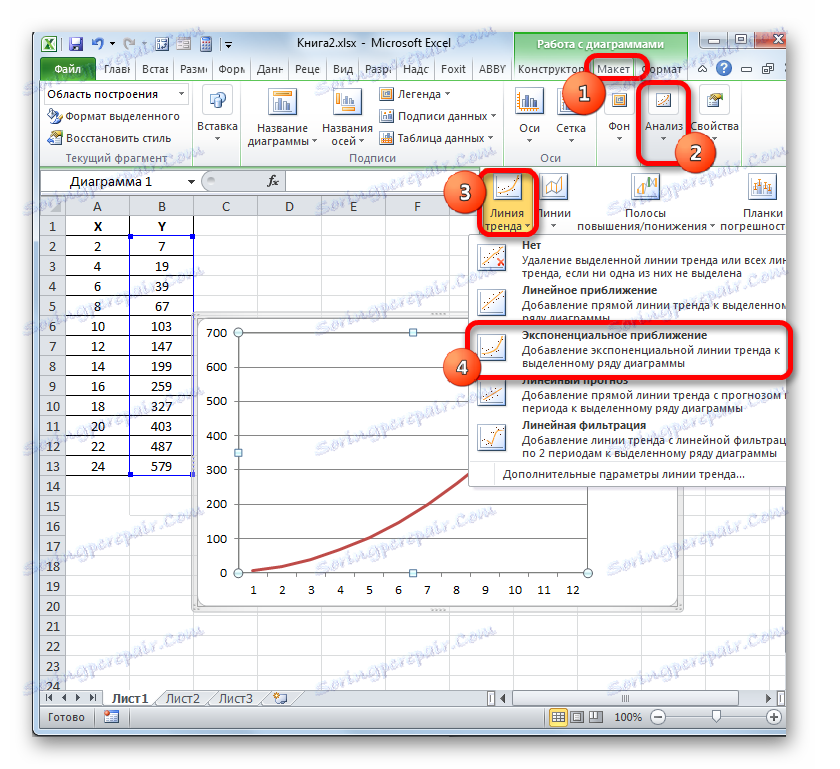
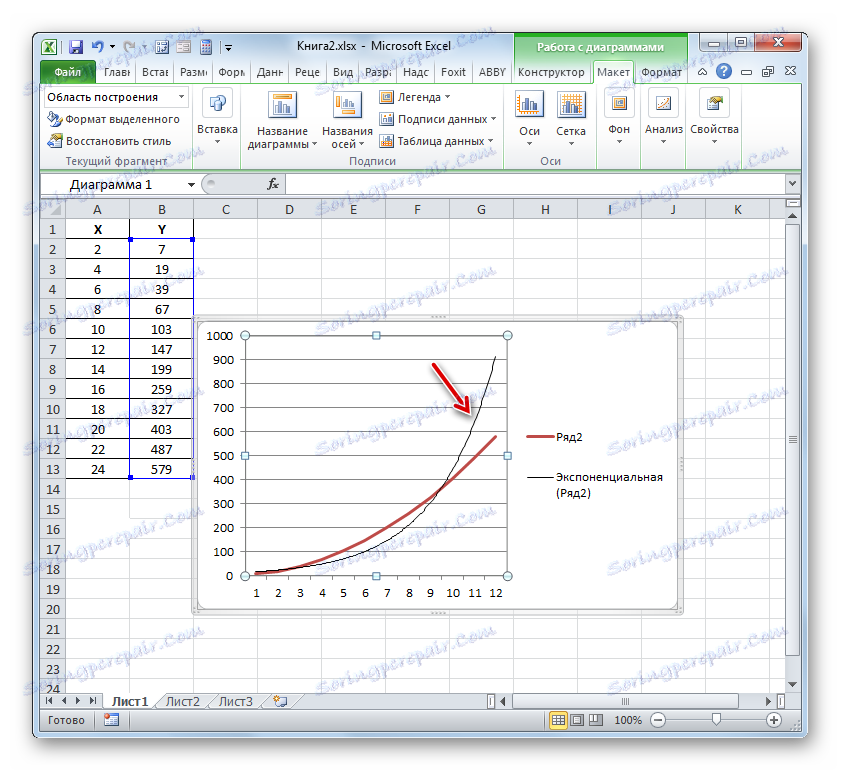
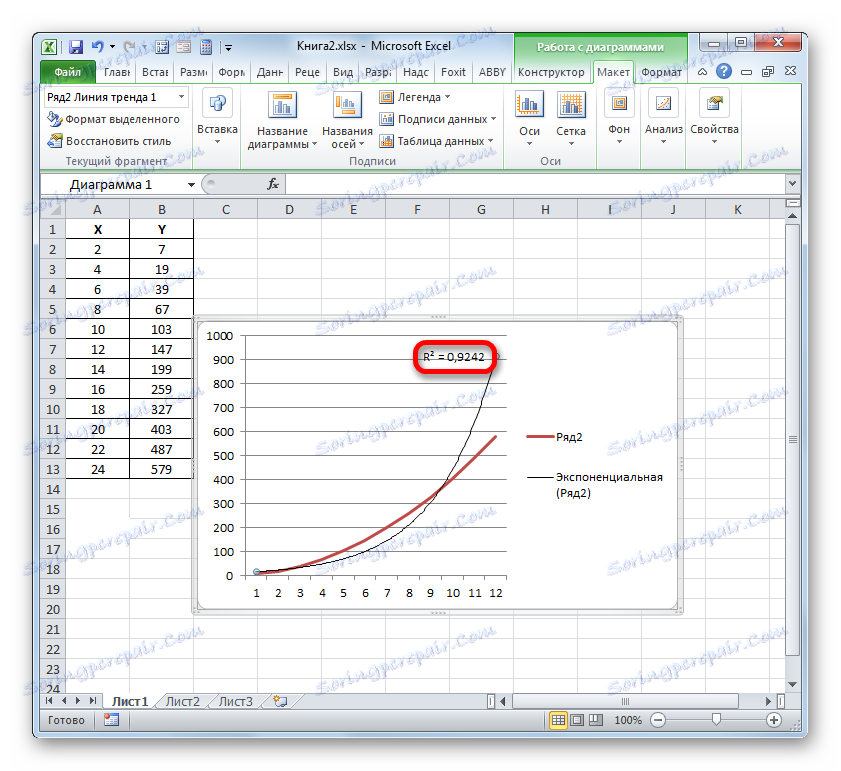
- Имаме графика въз основа на таблицата на аргументите и стойностите на функцията, която беше използвана за предишния пример. Нека изградим тенденция към него. Кликнете върху всяко място в областта на конструкцията, на която е поставена графиката с левия бутон на мишката. В този случай на лентата се появява допълнителен набор от раздели - "Работа с диаграми" . Отворете раздела "Оформление" . Кликваме върху бутона "Trend Line" , който се намира в полето "Анализ" . Появява се меню, показващо вида на тренд линията. Спираме селекцията на типа, който съответства на конкретната задача. За нашия пример изберете опцията "Експоненциално сближаване" .
- Excel изгражда тенденция директно върху равнината на изобразяване под формата на допълнителна черна крива.
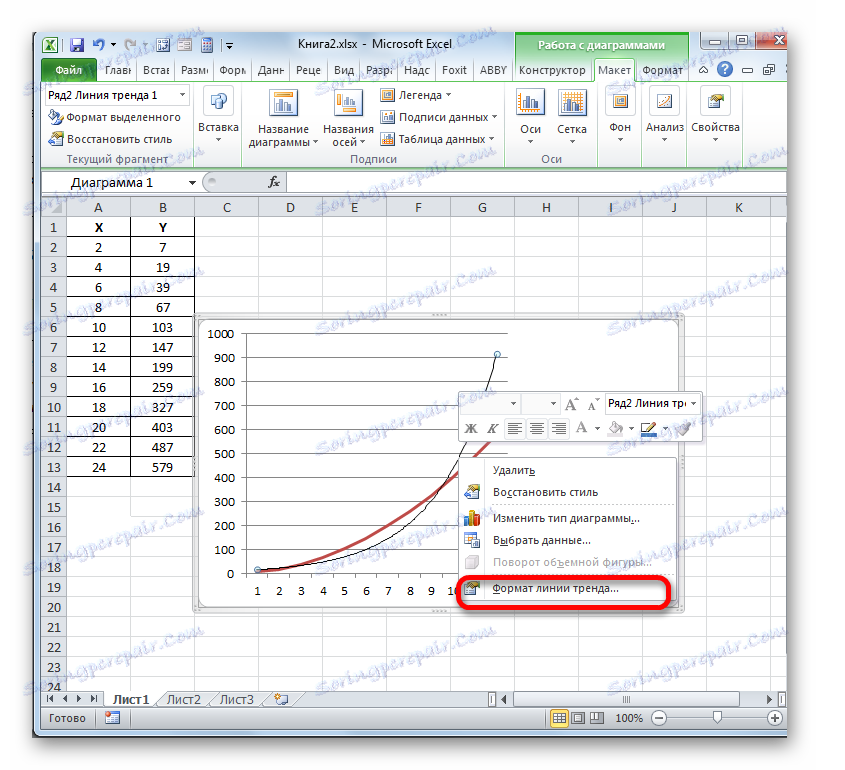
- Сега задачата ни е да покажем действителния коефициент на определяне. Щракнете с десен бутон върху линията на тенденцията. Конзолното меню се активира. Ние спираме селекцията в нея върху елемента "Trendline format ..." .
![Отворете прозореца за формат на линията на тенденциите в Microsoft Excel]()
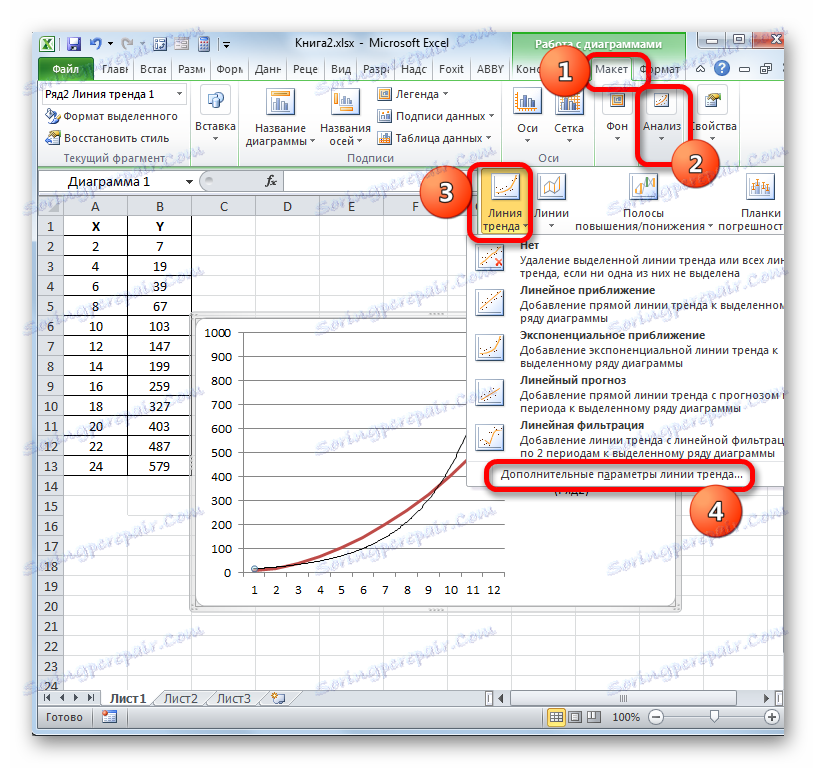
За да извършите прехода към прозореца на формата на тренда, можете да извършите алтернативно действие. Изберете линията на тенденцията, като кликнете върху нея с левия бутон на мишката. Преминаваме към раздела "Разпределение" . Кликваме върху бутона "Тенденция" в блока "Анализ" . В отворения списък кликнете върху най-новия елемент от списъка с действия - "Допълнителни параметри на тенденцията ..." .
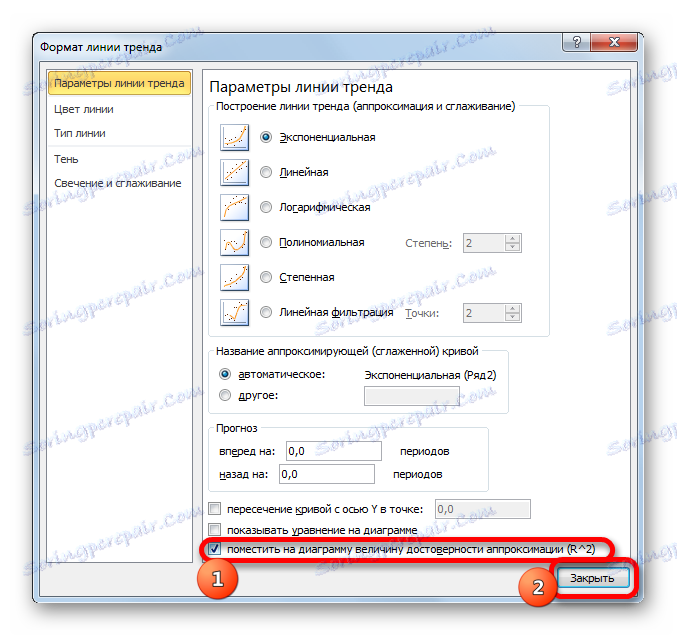
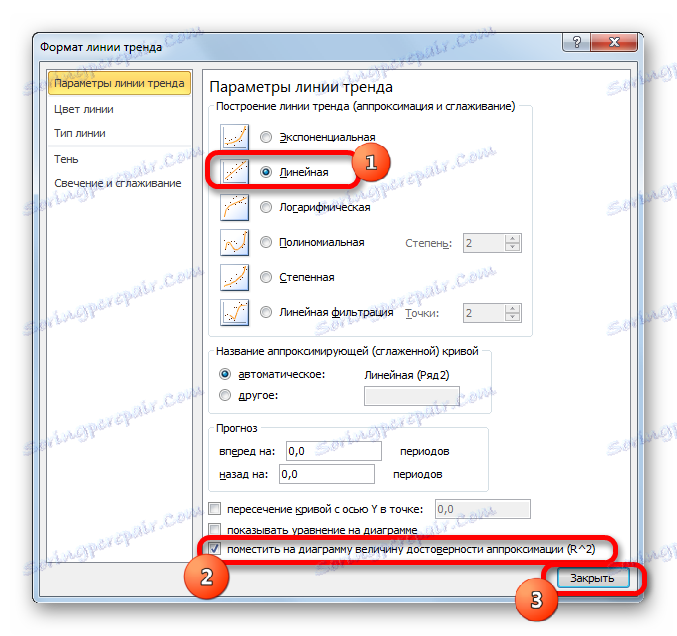
- След едно от двете по-горе действия се стартира прозорец на формат, в който могат да се направят допълнителни настройки. По-специално, за да изпълним задачата си, трябва да проверим квадратчето до "Поставете стойността на точността на сближаване (R ^ 2) на диаграмата" . Намира се в дъното на прозореца. Това означава, че по този начин включваме картографиране на коефициента на определяне на строителната площ. След това не забравяйте да кликнете върху бутона "Затваряне" в долната част на текущия прозорец.
- Стойността на надеждността на сближаването, т.е. стойността на коефициента на определяне, ще се покаже на листа в строителната зона. В този случай тази стойност, както виждаме, е 0.9242, която характеризира сближаването като модел с добро качество.
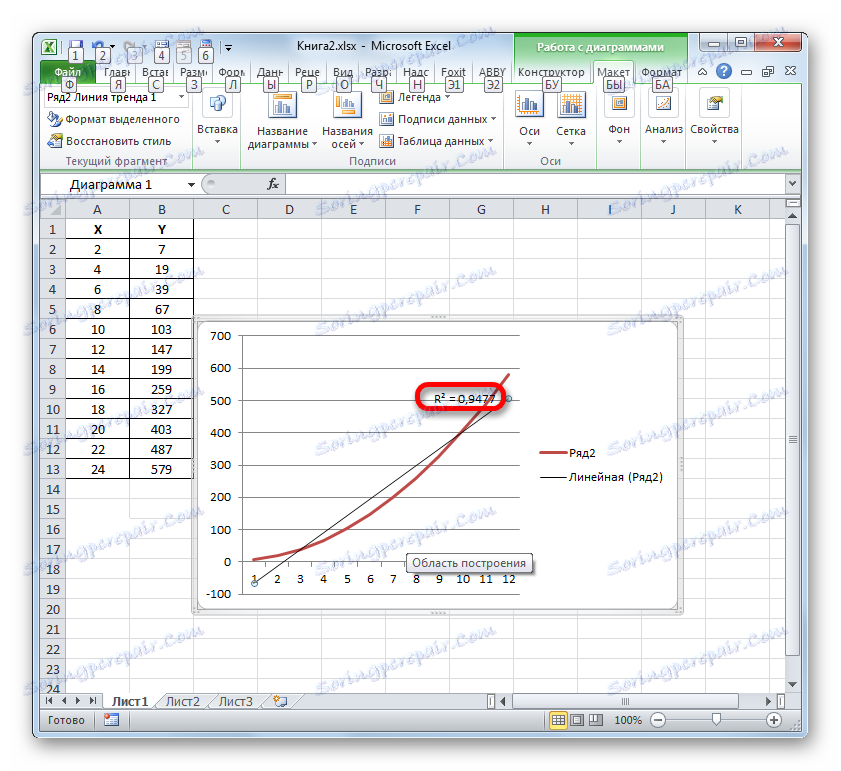
- Абсолютно по този начин, можете да настроите показването на коефициента на определяне за всеки друг тип тренд линия. Можете да промените типа на тренд линията, като преместите през бутона на лентата или контекстното меню в прозореца с параметри, както е показано по-горе. След това можете да превключите на друг тип в групата "Trend Line" в самия прозорец. Не забравяме да контролираме например квадратчето за отметка до "Поставете стойността на точността на приближение" в диаграмата . След като изпълните горните стъпки, кликнете върху бутона "Затваряне" в долния десен ъгъл на прозореца.
- При линеен тип линията на тенденцията вече има доверителна стойност на приблизителната стойност, равна на 0.9477, която характеризира този модел, като още по-надеждна от линията на тенденцията на експоненциалния тип, която разгледахме по-рано.
- По този начин, превключването между различните типове линии на тенденциите и сравняването на техните надеждни стойности на сближаване (коефициента на определяне), може да се намери вариантът, чийто модел най-точно описва представената графика. Вариантът с най-висок показател за коефициента на определяне ще бъде най-надежден. Въз основа на него можете да създадете най-точната прогноза.
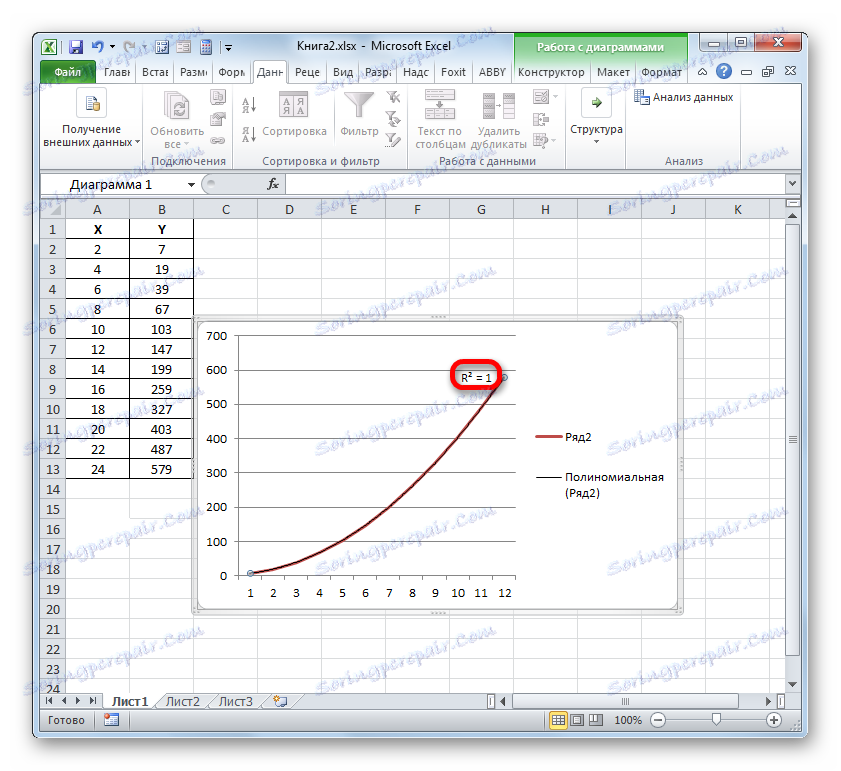
Например, за нашия случай успяхме да установим от опит, че най-високото ниво на надеждност има полиномен тип на втората степен на тренда. Коефициентът на определяне в този случай е 1. Това показва, че този модел е абсолютно надежден, което означава пълно премахване на грешките.
![Стойността на надеждността на сближаване за тип полином на тренд линия в Microsoft Excel]()
Но в същото време това изобщо не означава, че този тип тенденция е и най-надеждната за друга диаграма. Оптималният избор на вида на линията на тенденцията зависи от типа функция, на базата на която графиката е конструирана. Ако потребителят няма достатъчно знания, за да "предположи" най-добрия вариант, тогава единственият начин да се определи по-доброто прогнозиране е да се сравнят коефициентите за определяне, както беше показано в горния пример.
Прочетете още:
Изграждане на тренд линия в Excel
Сближаване в Excel
В Excel има две основни опции за изчисляване на коефициента на определяне: използването на оператора KVPIRSON и използването на инструмента "Regression" от пакета с инструменти "Анализ на данните" . В този случай първата от тези опции е предназначена за използване само в процеса на обработка на линейна функция, а друга възможност може да се използва в почти всички ситуации. Освен това е възможно да се покаже коефициентът на определяне за тренд линията на графиките като стойност на надеждността на приближението. С този индикатор е възможно да се определи вида на линията на тенденцията, която има най-високо ниво на сигурност за определена функция.