Разпознаване на текст в PDF файл онлайн.
Не винаги е възможно да извлечете текст от PDF файл, като използвате конвенционално копиране. Често страниците на тези документи са сканираното съдържание на техните хартиени версии. За да конвертирате такива файлове в напълно редактируеми текстови данни, се използват специални програми с функцията за оптично разпознаване на символи (OCR).
Такива решения са много трудни за изпълнение и следователно струват много пари. Ако трябва редовно да разпознавате текст с PDF, препоръчително е да закупите съответната програма. В редки случаи би било по-логично да се използва един от наличните онлайн услуги със сходни функции.
съдържание
Как да разпознаете текст от PDF онлайн
Разбира се, функцията OCR за онлайн услуги е по-ограничена в сравнение с пълните решения за настолни компютри. Но можете да работите с такива ресурси или безплатно, или с номинална такса. Основното е, че съответните уеб приложения се справят с основната си задача, а именно разпознаването на текст.
Метод 1: ABBYY FineReader Online
Фирмата за разработване на услуги е един от лидерите в областта на разпознаването на оптични документи. ABBYY FineReader за Windows и Mac е мощно решение за конвертиране на PDF в текст и по-нататъшна работа с нея.
Уеб страницата на програмата, разбира се, е по-лоша от функционалността. Въпреки това услугата разпознава текст от сканиране и снимки на повече от 190 езика. Поддържа конвертирането на PDF файлове в документи дума , Excel и т.н.
Онлайн услуга на ABBYY FineReader Online
- Преди да започнете да работите с инструмента, създайте си профил на сайта или влезте с профила си в Facebook, Google или Microsoft.
![Регистрирайте се в ABBYY FineReader Online]()
За да отворите прозореца за вход, кликнете върху бутона "Вход" в горната лента с менюта. - След като влезете, импортирайте желания PDF документ в FineReader, като използвате бутона "Качване на файлове" .
![Разпознаване на текст от PDF документ в онлайн услугата ABBYY FineReader Online]()
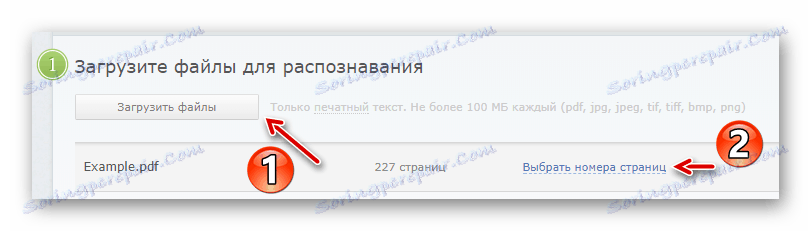
След това кликнете върху "Избор на номера на страници" и задайте желания интервал за разпознаване на текст. - След това изберете езиците в документа, формата на получения файл и кликнете върху бутона "Разпознаване" .
![Започнете разпознаването на текст от PDF документ в ABBYY FineReader Online]()
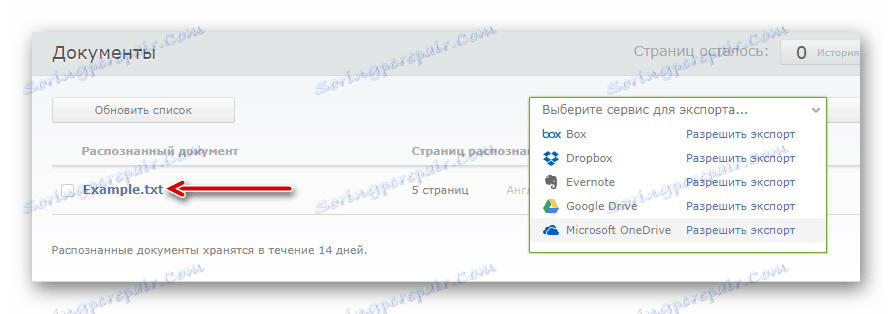
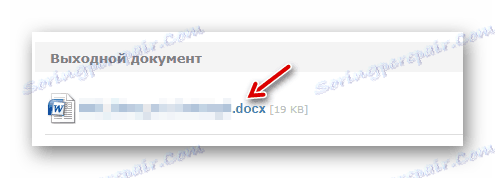
- След обработката, продължителността на която зависи изцяло от размера на документа, можете да изтеглите завършения файл с текстови данни, като щракнете върху името му.
![Изтегляне на завършения документ от онлайн услугата ABBYY FineReader Online]()
Или го експортирайте в една от наличните клауд услуги.

Услугата се отличава вероятно от най-точните алгоритми за разпознаване на текст върху изображения и PDF файлове. За съжаление, неговата безплатна употреба е ограничена до пет страници, обработени на месец. За да работите с по-обемни документи, трябва да си купите едногодишен абонамент.
Въпреки това, ако функцията OCR е много рядко необходима, ABBYY FineReader Online е чудесна възможност за извличане на текст от малки PDF файлове.
Метод 2: Безплатно онлайн OCR
Опростено и удобно обслужване за цифровизация на текст. Без да е необходима регистрация, ресурсът ви позволява да разпознавате 15 пълни PDF страници на час. Безплатно онлайн OCR напълно работи с документи на 46 езика и без разрешение поддържа три текстови формати за експортиране - DOCX, XLSX и TXT.
При регистрация потребителят може да обработва многостранични документи, но безплатният брой на тези страници е ограничен до 50 единици.
Онлайн услуга Безплатно онлайн OCR
- За да разпознаете текста от PDF файла като "гост", без разрешение за ресурса, използвайте съответния формуляр на главната страница на сайта.
![Разпознаване на PDF в онлайн услугата OCR Безплатно онлайн]()
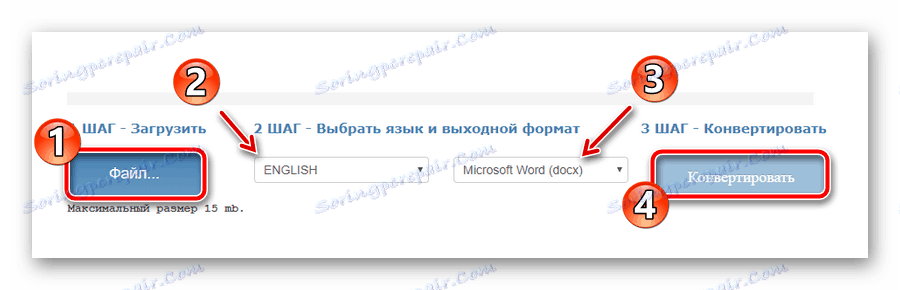
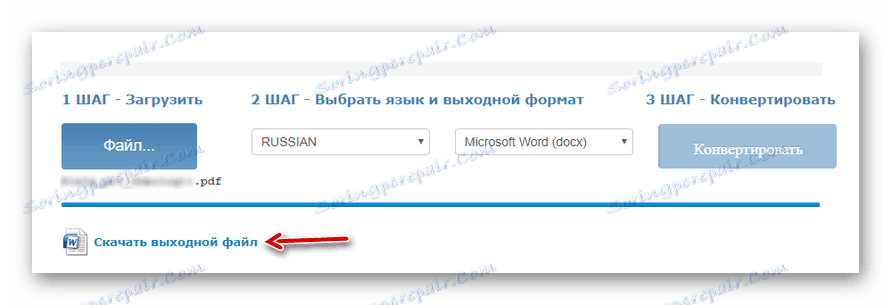
Изберете желания документ с помощта на бутона "Файл" , изберете основния език на текста, изходния формат, след което изчакайте изтеглянето на файла и кликнете върху "Convert" . - В края на процеса на цифровизация кликнете върху "Изтегляне на изходен файл", за да съхраните готовия документ заедно с текста на вашия компютър.
![Изтегляне на резултата от разпознаването на текст от PDF от онлайн безплатната онлайн услуга OCR]()
За оторизираните потребители поредицата от действия е малко по-различна.
- Използвайте бутона "Регистриране" или "Вход" в горната лента с менюта, за да създадете или да получите достъп до профила си в Free OCR.
![Създаване на акаунт в онлайн услугата Free Online OCR]()
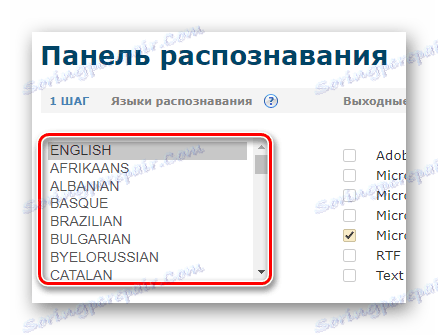
- След упълномощаване в панела за разпознаване, задръжте натиснат клавиша "CTRL" и изберете до два езика на източника от предоставения списък.
![Определяне на езиците на източника на документи за разпознаване на текст в Free Online OCR]()
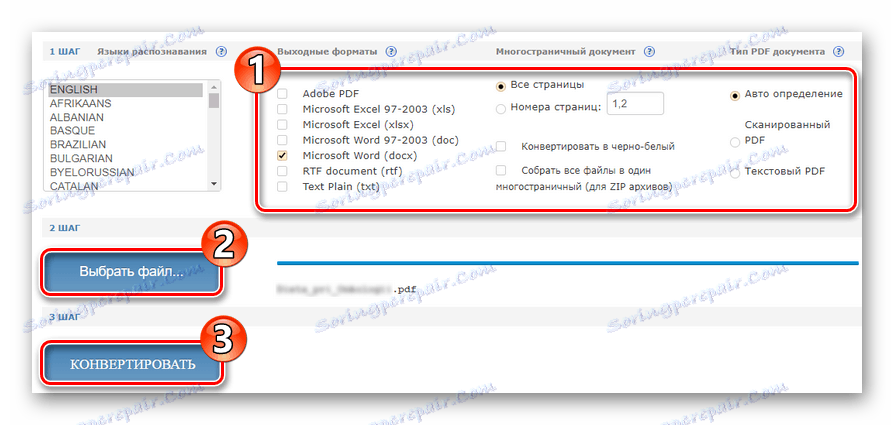
- Посочете допълнителни параметри за извличане на текст от PDF и щракнете върху бутона "Избор на файл", за да качите документа на услугата.
![Започнете да разпознавате PDF документ в онлайн безплатната онлайн услуга OCR]()
След това, за да започнете разпознаването, кликнете върху "Конвертиране" . - След обработката на документа кликнете върху връзката с името на изходния файл в съответната колона.
![Изтегляне на завършен DOCX файл от онлайн безплатната онлайн услуга OCR]()
Резултатът от разпознаването ще бъде съхранен незабавно в паметта на вашия компютър.
Ако трябва да извлечете текст от малък PDF документ, можете спокойно да прибегнете до инструмента, описан по-горе. За да работите с големи файлове, ще трябва да купите допълнителни символи в Free Online OCR или да прибягвате до друго решение.
Метод 3: NewOCR
Напълно безплатна OCR услуга, която ви позволява да извличате текст от почти всички графични и електронни документи като DjVu и PDF. Ресурсът не налага ограничения за размера и броя разпознаваеми файлове, не изисква регистрация и предлага широк спектър от свързани функции.
NewOCR поддържа 106 езика и е в състояние да обработва правилно дори сканираните документи с ниско качество. Възможно е ръчно да изберете областта за разпознаване на текст на страницата на файла.
- Така че, можете да започнете работа с ресурса незабавно, без да е необходимо да извършвате ненужни действия.
![Изтегляне на PDF файл за разпознаване в онлайн услугата NewOCR]()
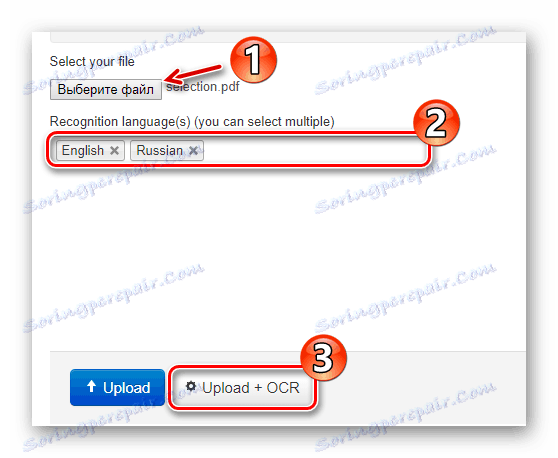
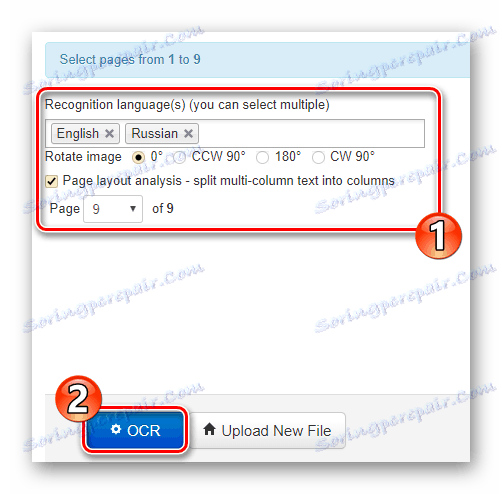
Директно на главната страница има формуляр за импортиране на документа на сайта. За да качите файл в NewOCR, използвайте бутона "Избор на файл" в секцията "Избор на файл" . След това в полето "Езици за разпознаване" изберете един или повече езика на оригиналния документ, след което кликнете върху "Upload + OCR" . - Задайте любимите си настройки за разпознаване, изберете желаната страница, за да извлечете текста и кликнете върху бутона "OCR" .
![Настройване и стартиране на разпознаване на текст от PDF в онлайн услугата NewOCR]()
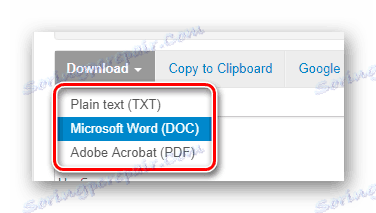
- Превъртете надолу малко и намерете бутона "Изтегляне" .
![Изтеглете текст, извлечен в NewOCR, на компютър]()
Кликнете върху него и изберете желания формат за изтегляне в падащия списък. След това завършеният файл с извлечения текст ще бъде изтеглен на вашия компютър.
Инструментът е удобен и разпознава всички знаци в достатъчно високо качество. Обработката на всяка страница от импортирания документ PDF обаче трябва да се стартира независимо и да се показва в отделен файл. Можете, разбира се, незабавно да копирате резултатите от разпознаването в клипборда и да ги обедините с други хора.
Въпреки това, предвид горния нюанс, големи количества текст, използващи NewOCR, са много трудни за извличане. Услугата се справя с малки файлове "с взрив".
Метод 4: OCR.Спейс
Един прост и разбираем ресурс за дигитализиране на текст ви позволява да разпознавате PDF документи и да извеждате резултата в TXT файл. Няма ограничение за броя страници. Единственото ограничение е, че размерът на входния документ не трябва да надвишава 5 мегабайта.
- Не е необходимо да се регистрирате за работа с инструмента.
![Импортирайте PDF файла в онлайн услугата OCR.Space]()
Просто кликнете върху връзката по-горе и качете PDF документа на уебсайта от компютъра си, като използвате бутона "Избор на файл" или от мрежата, като кликнете върху връзката. - В падащия списък "Изберете език за OCR" изберете езика на импортирания документ.
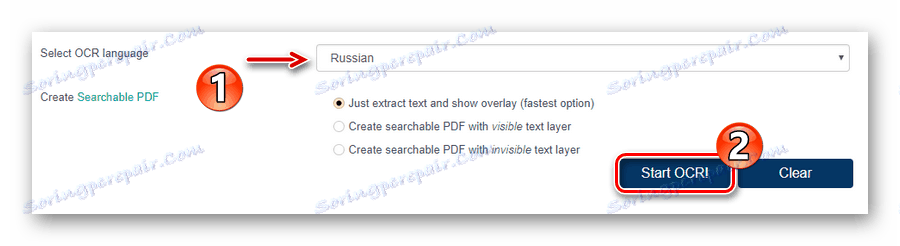
![Стартиране на процеса на разпознаване на PDF документ в онлайн услугата OCR.Space]()
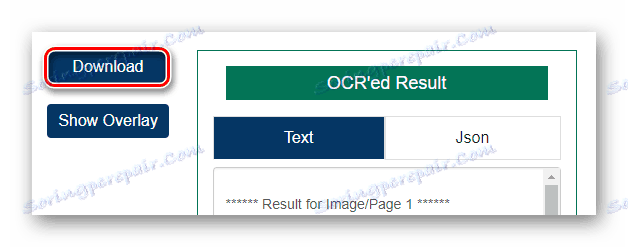
След това стартирайте процеса за разпознаване на текст, като кликнете върху бутона "Стартиране на OCR!" . - В края на обработката на файла прегледайте резултата в полето "OCR'ed Result" и кликнете върху "Download", за да изтеглите завършения документ TXT.
![Изтегляне на резултата от разпознаването на PDF файл от онлайн услугата OCR.Space]()

Ако просто трябва да извлечете текста от PDF файла и окончателното форматиране изобщо не е важно, OCR.Space е добър избор. Единственият документ трябва да е "едноезичен", тъй като не се предоставя признаване на два или повече езика едновременно в услугата.
Вижте също: Безплатни аналози на FineReader
Оценявайки онлайн представените инструменти в статията, трябва да се отбележи, че ABBYY FineReader Online обработва функцията OCR най-точно и точно. Ако максималната точност на разпознаването на текст е важна за вас, най-добре е да разгледате този конкретен вариант. Но за да плати за него, най-вероятно, също трябва.
Ако се нуждаете от дигитализиране на малки документи и сте готови да коригирате грешки в услугата сами, препоръчително е да използвате NewOCR, OCR.Space или Free OCR.